CS 330 Lecture 35 – Parsing
Dear students,
We started writing our own lexer last time. We were trying to model in code this DFA that we drew on the board:
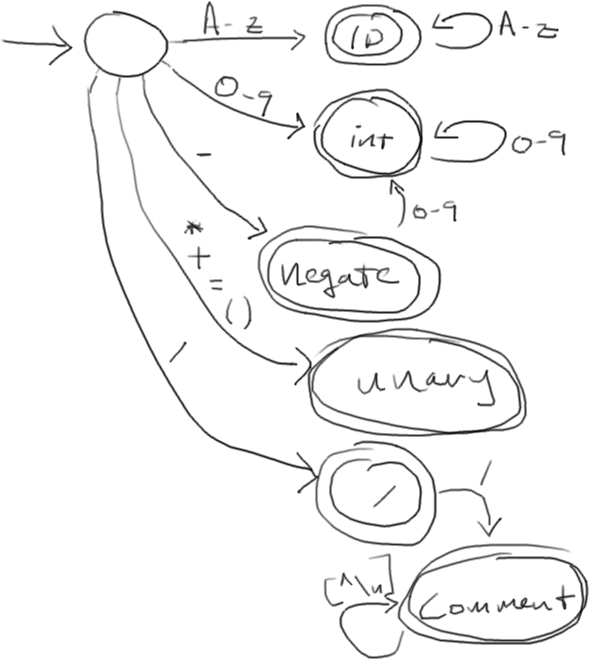
Now, you might not have seen it, but we were actually playing a game of Chutes and Ladders. Each character in our source code was like a roll that moved us forward on the DFA. Once we reach a final state, we slip back to the starting state. But in our hands is a brand new baby token that we drop in a basket for later consumption. Sadly, we only got the single character tokens. Lexing single characters is not very impressive. Let’s augment our lexer to handle integer literals.
We first start with a transition to a special function for dealing with integers:
else if (has(/\d/)) {
integer();
}
And we’ll add a function for this more complex state:
function integer() {
while (iToRead < program.length && has(/\d/)) {
consume();
}
emitToken(INTEGER);
};
Let’s handle identifiers similarly:
else if (has(/[A-Za-z]/)) {
identifier();
}
However, what constitutes a legal identifier in most programming languages? Can we name a variable for? Or if? No. These are keywords. Instead of tweaking our DFA to have special states for keywords, it’s common practice to special case them after you’ve lexed out an identifier:
function identifier() {
while (iToRead < program.length && has(/[A-Za-z]/)) {
consume();
}
if (tokenSoFar == 'rectangle') {
emitToken(RECTANGLE);
} else if (tokenSoFar == 'circle') {
emitToken(CIRCLE);
} else {
emitToken(IDENTIFIER);
}
};
We should be able to lex integer literals and identifiers now. Let’s try a program that has both!
56 foo
It fails on the whitespace. Our lexer must be ready for that too! But hey, whitespace isn’t significant in many languages, so there’s really no reason to emit a token for it. We just consume and toss any spaces or tabs:
else if (has(/[ \t]/) {
consume();
tokenSoFar = '';
}
How about -? This operator is the bane of lexing. Sometimes it’s a unary operator, negating its operand. Other times its a binary operator. We’ll determine how to handle it by deferring to a helper:
else if (has(/-/)) {
minus();
}
The helper function will peek ahead to figure out what kind of minus it is:
function minus() {
consume();
if (has(/\d/)) {
integer();
} else {
emitToken(MINUS);
}
}
How about division? Well, if we see two slashes, maybe we’re looking at a comment? We’ll need to solve this similarly. First, our condition in lex:
else if (has(/\//)) {
divide();
}
The helper function will peek ahead to distinguish between the mathematical operator and a comment. Comments, like whitespace, we can discard, as they will have no impact on the interpretation of our program.
divide = function() {
consume();
if (has(/\//)) {
consume();
while (has(/[^\n]/)) {
consume();
}
tokenSoFar = '';
} else {
emitToken(DIVIDE);
}
}
That rounds out our lexer, the first stage of getting our computer to understand us. We have broken the program up into byte-size pieces.
Now it is time to assemble these tokens into a model of our program. That’s the role of the parser. We’re going to simplify our language in our first draft of our parser. Eventually we’ll add variable assignments, loops, and maybe functions.
To make a model of our program, we need to think about what a program is. We can describe a program’s anatomy by defining its grammar:
program : statement* EOF statement : RECTANGLE expr expr expr expr expr : INTEGER
The parser’s job is to build up a representation of our program in a language that the computer does know how to execute. It doesn’t know our shaper language, but it does know Javascript! So, we create classes for all our program parts:
function Block(statements) {
}
function StatementRectangle(left, top, width, height) {
}
function ExpressionInteger(literal) {
}
We need to model how these behave when our program is executed. Let’s add an evaluate method to each:
function Block(statements) {
this.evaluate = function() {
statements.forEach(statement => statement.evaluate());
}
}
function StatementRectangle(left, top, width, height) {
this.evaluate = function() {
var l = left.evaluate();
var t = top.evaluate();
var w = width.evaluate();
var h = height.evaluate();
context.fillRect(l, t, w, h);
}
}
function ExpressionInteger(literal) {
this.evaluate = function() {
return literal;
}
}
We also need to add a place for our output to show up. We add a canvas element to the HTML:
<canvas id="canvas" width="400" height="300" style="background-color: lightgray;"></canvas>
And grab a reference to it and the drawing context in Javascript:
var canvas = document.getElementById('canvas');
var context = canvas.getContext('2d');
Someone could write a shaper program directly in our Javascript abstractions:
new Block([new StatementRectangle(new ExpressionInteger(0),
new ExpressionInteger(0),
new ExpressionInteger(480),
new ExpressionInteger(320))
]);
But this would be like us writing in assembly. We have a higher-level language. We need a tool to translate from high to low. Enter our Parser, which is structured very similarly to our Lexer:
function Parser(tokens) {
var iToParse;
function has(tokenType) {
return iToParse < tokens.length && tokens[iToParse].type == tokenType;
}
function consume() {
iToParse += 1;
}
this.parse = function() {
iToParse = 0;
...
}
}
We have functions asserting that certain tokens are on the horizon and for advancing past them. Now, the particular elegance of a state machine emerges in the rest of the code. It turns out that we just need to write a function for each of the so-called non-terminals in our grammar:
function program() {
}
function statement() {
}
function expression() {
}
Function program tries to parse a sequence of statements up until EOF:
function program() {
var statements = [];
while (!has(EOF)) {
statements.push(statement());
}
return new Block(statements);
}
Function statement tries to parse a rectangle command:
function statement() {
if (has(RECTANGLE)) {
consume();
var l = expression();
var t = expression();
var w = expression();
var h = expression();
return new StatementRectangle(l, t, w, h);
} else {
throw "Unexpected token: " + tokens[iToParse].source;
}
}
And function expression tries to parse an integer literal:
function expression() {
if (has(INTEGER)) {
var e = new ExpressionInteger(parseInt(tokens[iToParse].source));
consume();
return e;
} else {
throw "Unexpected token: " + tokens[iToParse].source;
}
}
That’s really the core our parsing. We just need to get the ball rolling in parse:
this.parse = function() {
iToParse = 0;
return program();
}
Whoever gets the results can choose to evaluate our tree when they are ready. We will do so immediately in our onchange callback:
var lexer = new Lexer(editor.value);
var tokens = lexer.lex();
var parser = new Parser(tokens);
var ast = parser.parse(); // ast -> abstract syntax tree
ast.evaluate();
We should see our program come to life.
Here’s your TODO list for next time:
- I am at the Wisconsin Math Council annual conference Wednesday through Friday. We will not have lecture. Instead I am recording some videos on parsing that I ask you to watch before next Monday. Your quarter sheet is to write a program in this language we’ve been designing. Draw something interesting. Feel free to use colors, loops, and the
timeparameter. I will post our interpreter and send you a link with the videos. If you want to extend the language for your program, you are free to do so, but I ask that you host your code somewhere and send me a link to it.
See you in a week!
